
In einen ersten Beitrag habe ich dargestellt, wie man eine WordPress-Website für die Nutzung der Google Search Console einrichtet. Nur wenige Stunden nach der Einrichtung sind die Datenübersichten der Google Search Console (GSC) natürlich noch leer. Ich verwende daher hier die Ergebnisse einer anderen Website, um die verschiedenen Auswertungsebenen der GSC darzustellen. Bei dieser Website handelt es sich nicht um einen WordPress-Blog, dort wird das Content Management System Yellow genutzt.
Die Übersichtsseite der Google Search Console
Werfen wir zunächst einen Blick auf die Übersichtsseite der GSC:
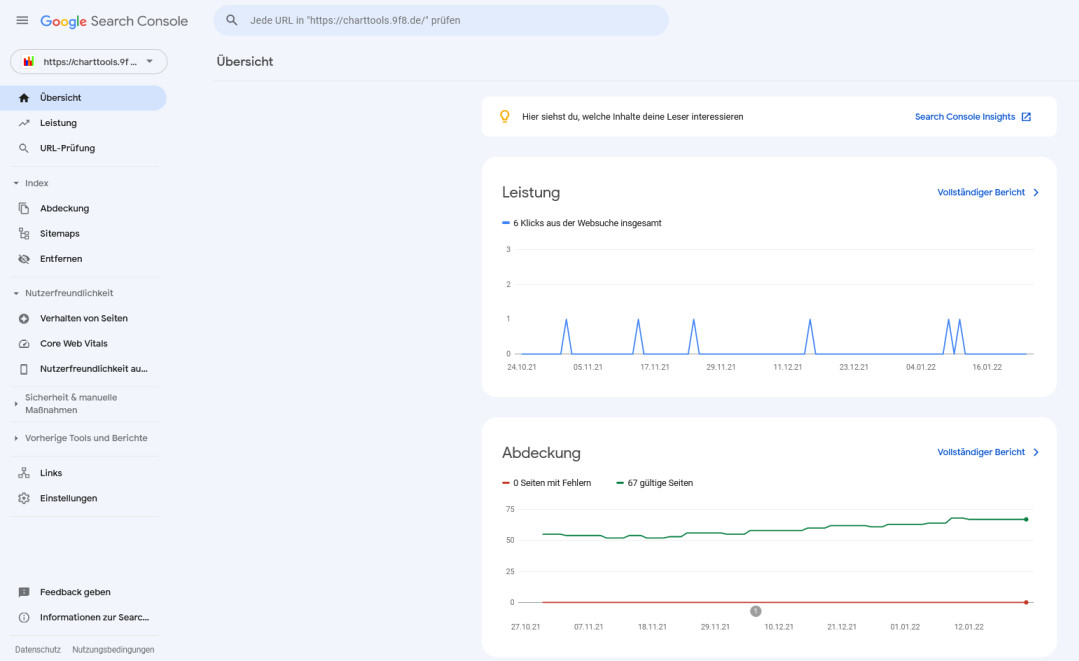
Mit sieht zunächst die Bereiche Leistung und Abdeckung. Leistung meint: Aufruf der Seite über die Google Suche, Abdeckung steht für den Umfang der Seiten im Google Suchindex.
Weiter unter erscheint ein weiterer Bereich:
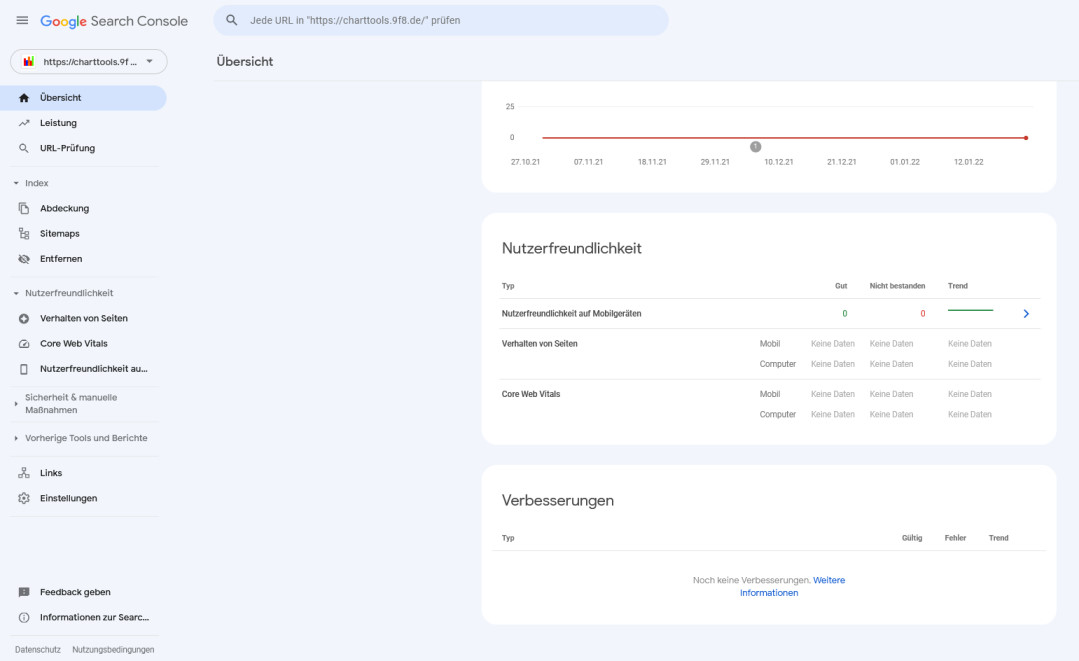
Hier werden angaben zur Benutzerfreundlichkeit und Verbesserungsvorschläge gemacht. Beide Bereiche sind im Falle der hier untersuchten Seite leer.
Leistung
Unter Leistung versteht man hier die Zahl der Aufrufe über die Google Suchmaschine. Dabei erhält man Informationen über die am häufigsten verwendeten Suchbegriffe:
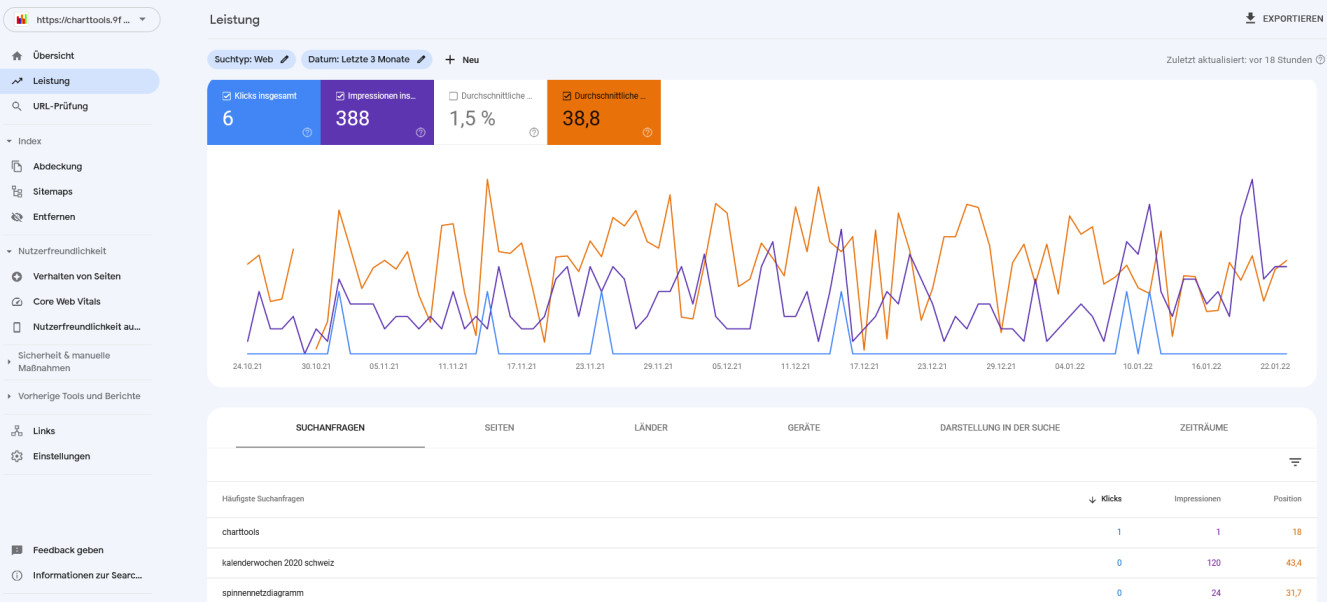
Auch eine Auswertung zu den am häufigsten über die Google Suche aufgerufenen Seiten ist möglich:
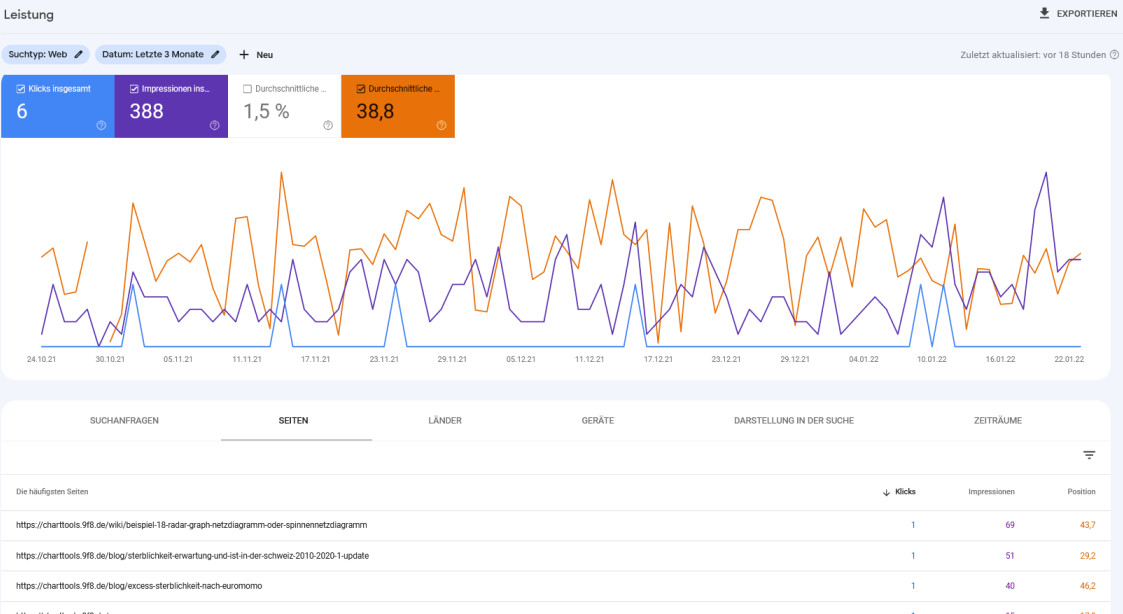
In der gleichen Art können auch Informationen zu den für die Suche verwendeten Geräten und zu den Herkunftsländern der Sucher aufgerufen werden.
Abdeckung
Der Bereich Abdeckung zeigt, in welchem Umfang die einzelnen Seiten einer Website im Google Suchindex enthalten sind. ein Abfrage bei Google mit site:https://charttools.9f8.de ergibt ein Suchergebnis von 40 Seiten.
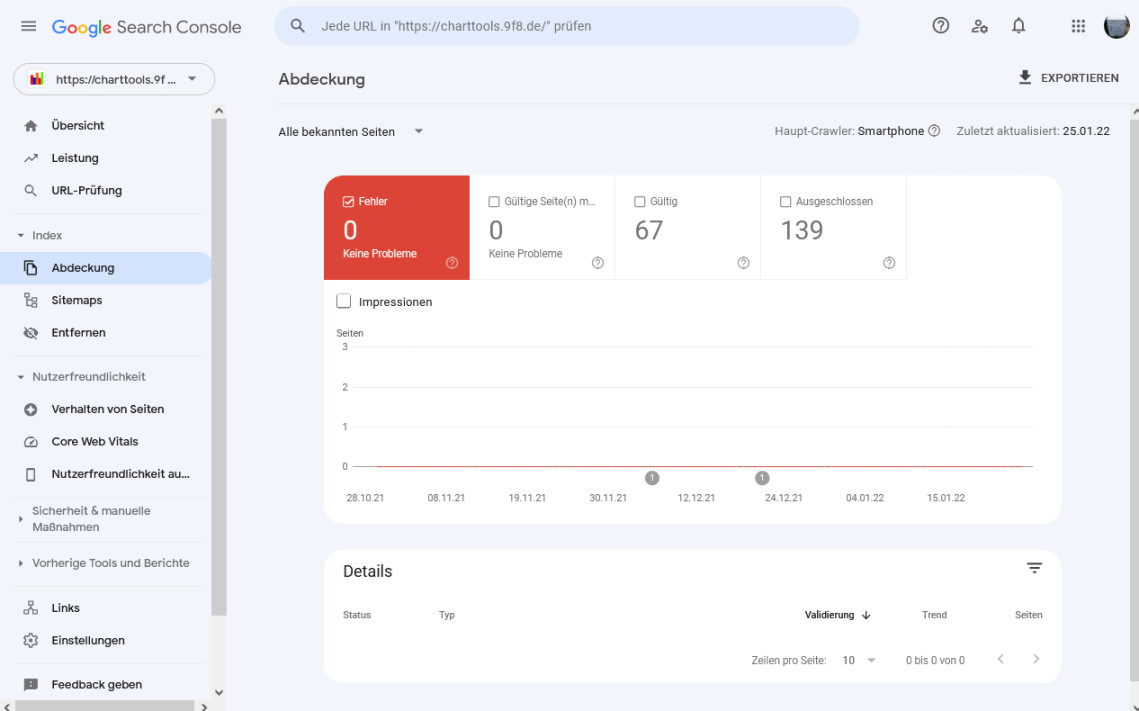
Die GSC zeigt, dass 67 Seiten enthalten sein sollen und 139 Seiten ausgeschlossen sind. Man kann jetzt die beiden Bereiche aktivieren, um zusätzliche Informationen zu erhalten.
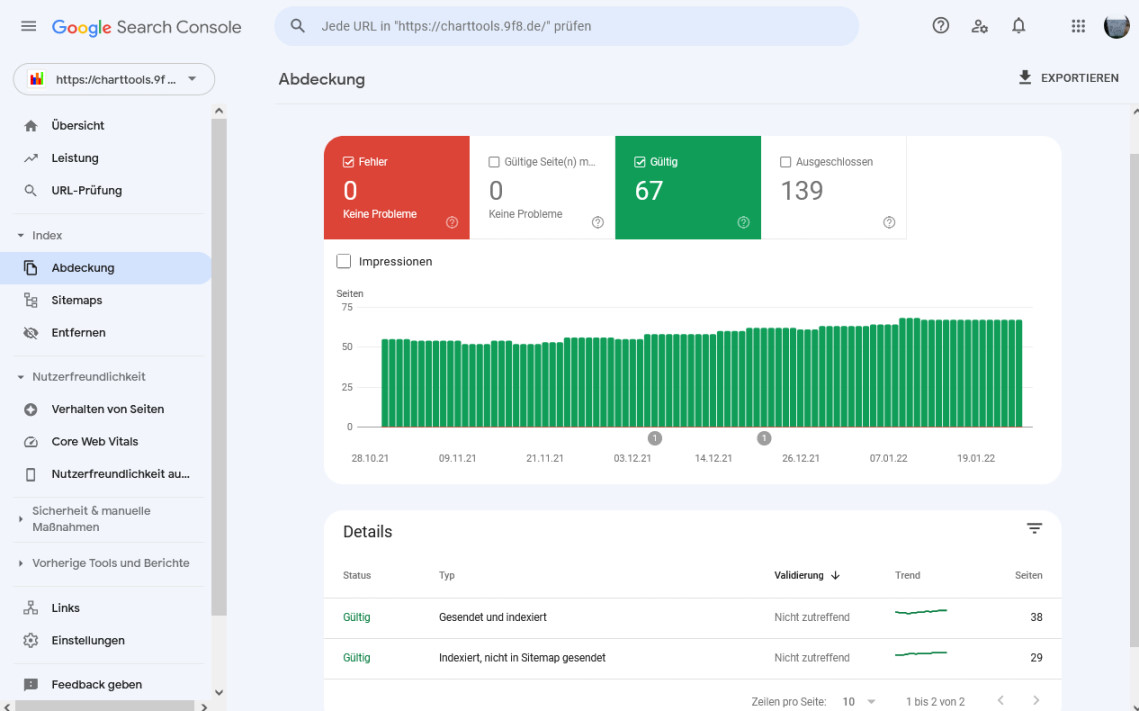
Man sieht jetzt, dass von den insgesamt 67 gültigen Seiten
- 38 gesendet und indiziert sind
- 29 zwar indiziert sind , aber nicht in der Sitemap gesendet wurden.
Mit dem Thema Sitemap werde ich mich später noch einmal genauer beschäftigen. Man kann in der GSC feststellen, dass für https://charttools.bpgs.de erfolgreich eine Sitemap eingereicht wurde und dass diese Sitemap 90 Einträge enthält, wovon 38 als gültig erkannt wurden und 52 ausgeschlossen wurden.
In der Übersicht zu den ausgeschlossenen Seiten werden ebenfalls mehrere Kategorien aufgelistet, die Aufschluss darüber geben, warum eine Seite ausgeschlossen wurde.
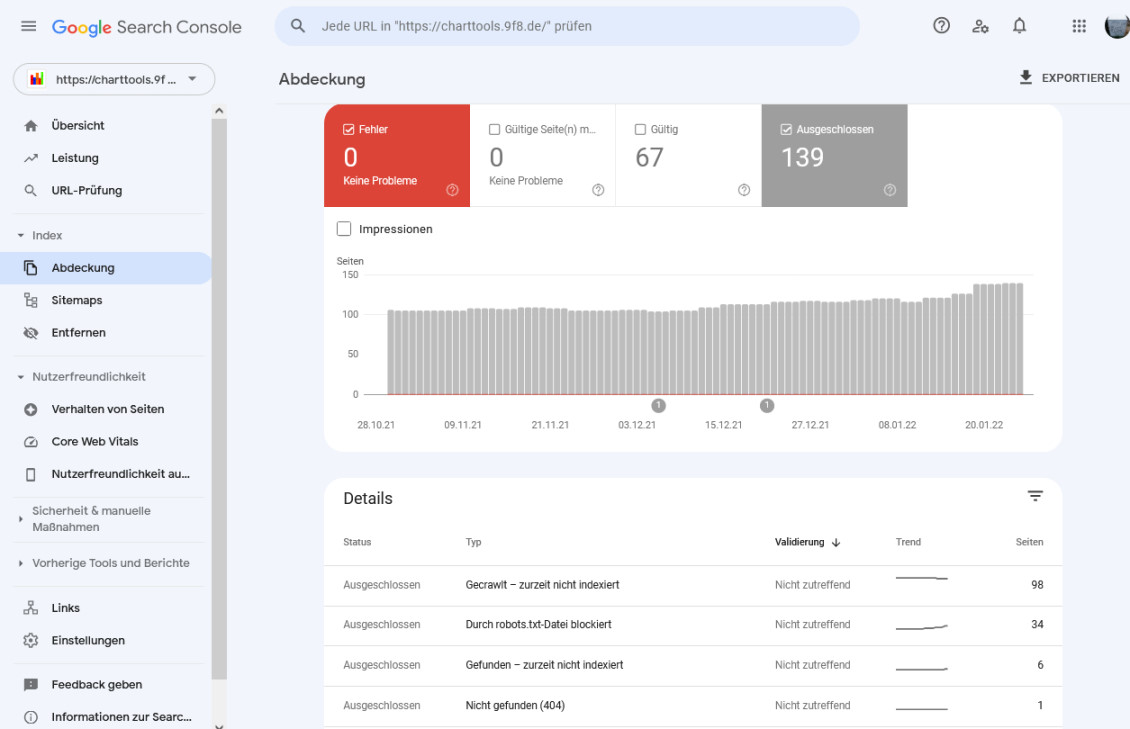
Es gibt
- 98 Seiten, die gecrawlt wurden aber noch nicht indiziert sind
- 34 Seiten, die durch die Datei robots.txt blockiert wurden
- 9 Seiten, die zwar gefunden wurden, aber noch nicht indiziert sind
- 1 Seite wurde nicht gefunden
Mit einem Klick auf die jeweilige Gruppe bekommt man eine Auflistung der jeweils betroffenen Seiten
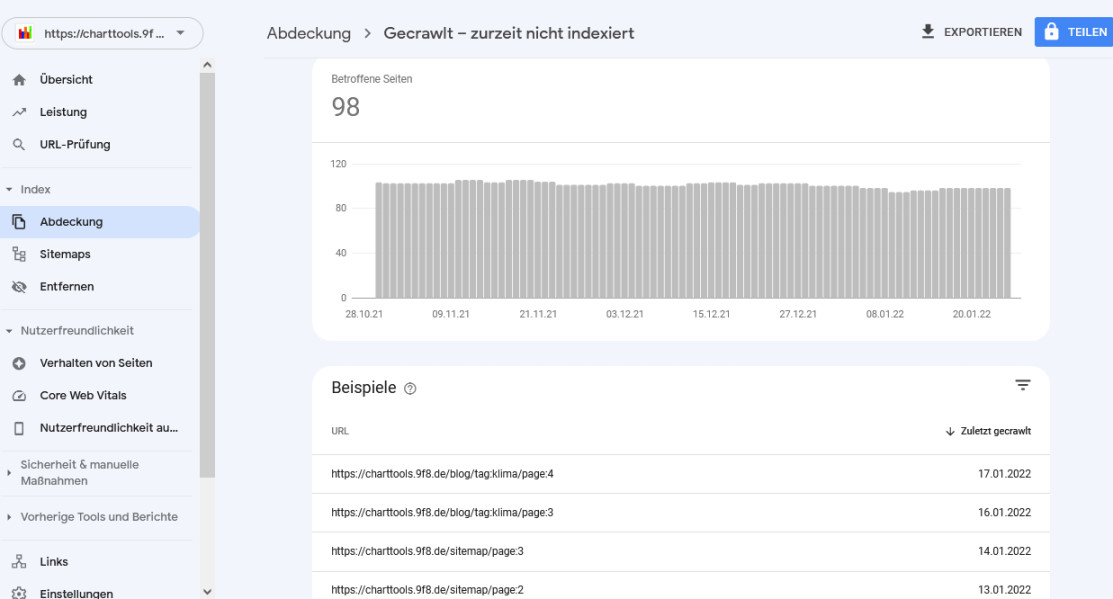
Man sieht zu jeder Seite das Datum, wann sie zuletzt gecrawlt wurde. Die einzelnen Seiten kann man nun auch anklicken um
- die Seiten-URL zu kopieren
- die Seite direkt aufzurufen
- sich weitere Information zu dieser Seite anzusehen
Ein Beispiel mit Informationen zu einer Seite (hier die Seite https://charttools.9f8.de/blog/sterblichkeit-erwartung-und-ist-in-der-schweiz-2010-2021) sieht so aus:
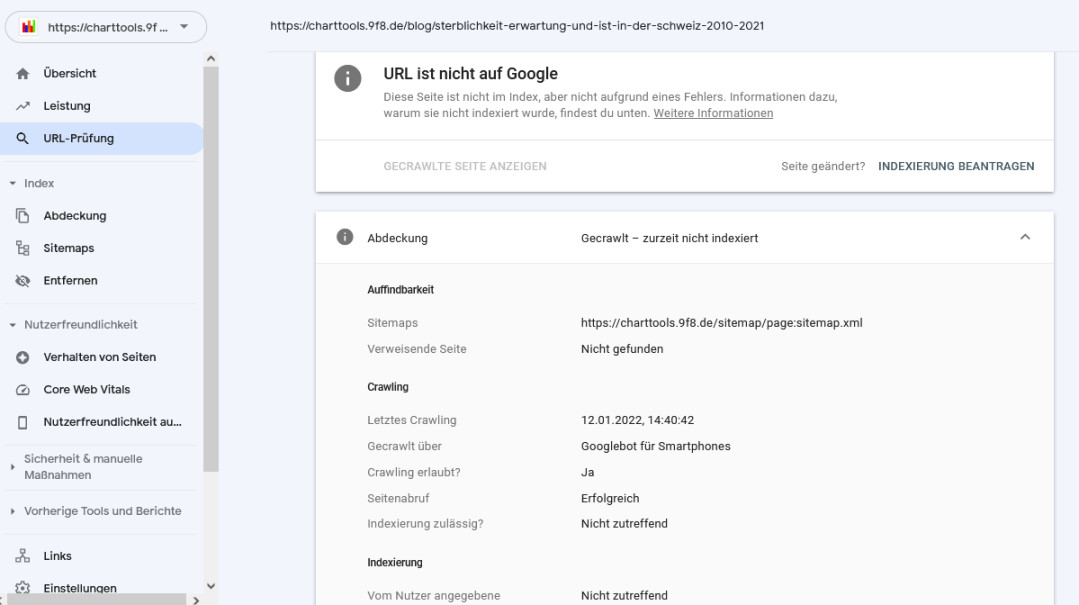
Die gleichen Informationen zur Einzelseite kann man auch direkt über den Punkt URL-Prüfung aufrufen.
Nutzerfreundlichkeit
Die unter dem Menüpunkt Nutzerfreundlichkeit aufgelisteten Einzelpunkt:
- Verhalten von Seiten
- Code Web Vitals
- Nutzerfreundlichkeit auf Mobilgeräten
sind zu dieser Beispielwebsite alle leer.
Sicherheit und manuelle Maßnahmen
Beide Unterpunkt zeigen, dass derzeit kann Handlungsbedarf besteht oder zumindest keiner erkannt wurde:
Links
In der Übersicht zu Links werden Links, also Verknüpfungen zu der untersuchten Website aufgelistet, und zwar solche, die von anderen Websites kommen, aber auch solche, die innerhalb der Website selbst bestehen.
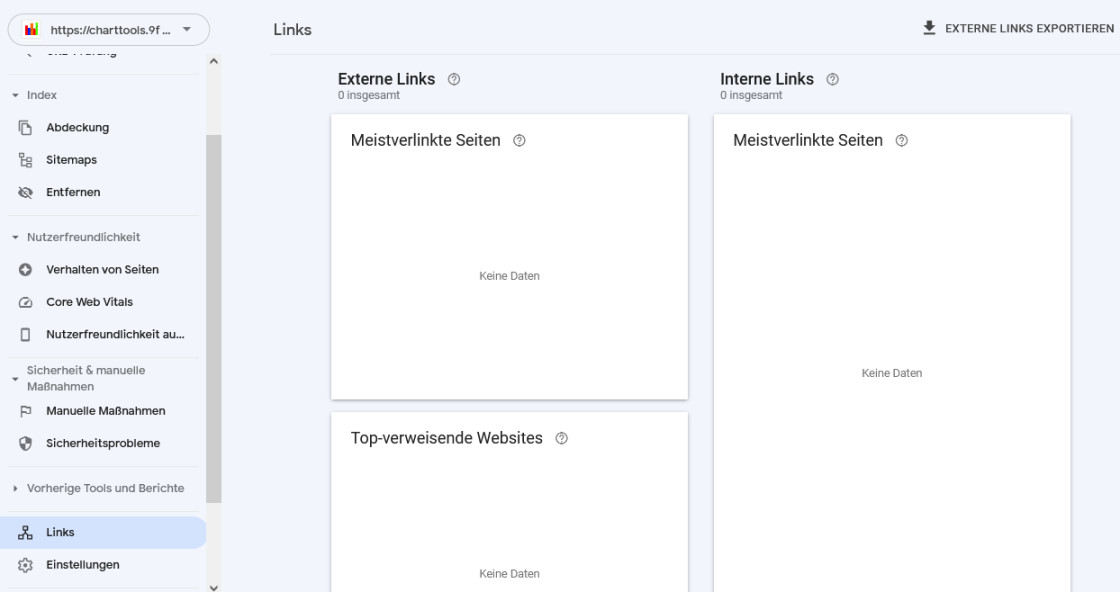
Man sieht hier, dass alle Bereiche leer sind. Das scheint mir fraglich, denn zumindest bei den internen Links müssten Informationen vorhanden sein.
Einstellungen
Kommen wir abschließend zu einem weiteren umfangreichen Punkt, dem Bericht über die Einstellungen. Die Übersichtsseite dazu sieht so aus:
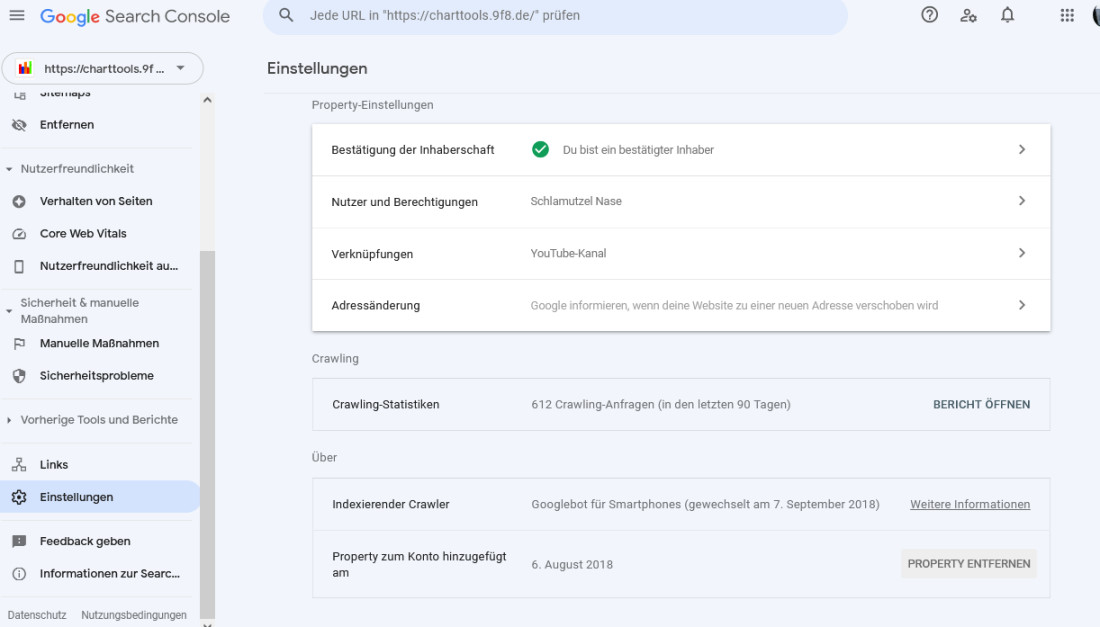
Man sieht zunächst drei Hauptbereiche:
- Property-Einstellungen
- Crawling
- Über
Property-Einstellungen
- Bestätigung der Inhaberschaft – dieser Aspekt wurde bereits in einem früheren Beitrag zur Google Search Console hier im Blog behandelt.
- Nutzer und Berechtigungen – hier können weitere Nutzer hinzugefügt werden
- Verknüpfungen
- Adressänderung – dieser Punkt wird relevant, wenn man den Inhalt einer Website zu einer neuen Adresse verschiebt. Das betrifft auch Änderungen von http auf https
Crawling Statistiken
In der Gesamtübersicht sieht man bereits, dass während der letzten 90 Tage 612 Crawling-Abfragen verarbeitet wurden (die Übersicht einen Tag später zeigt an gleicher Stelle 605). Diese Angaben kann man nun weiter untersuchen. Zuerst wird der zeitliche Verlauf der Abfragen dargestellt:
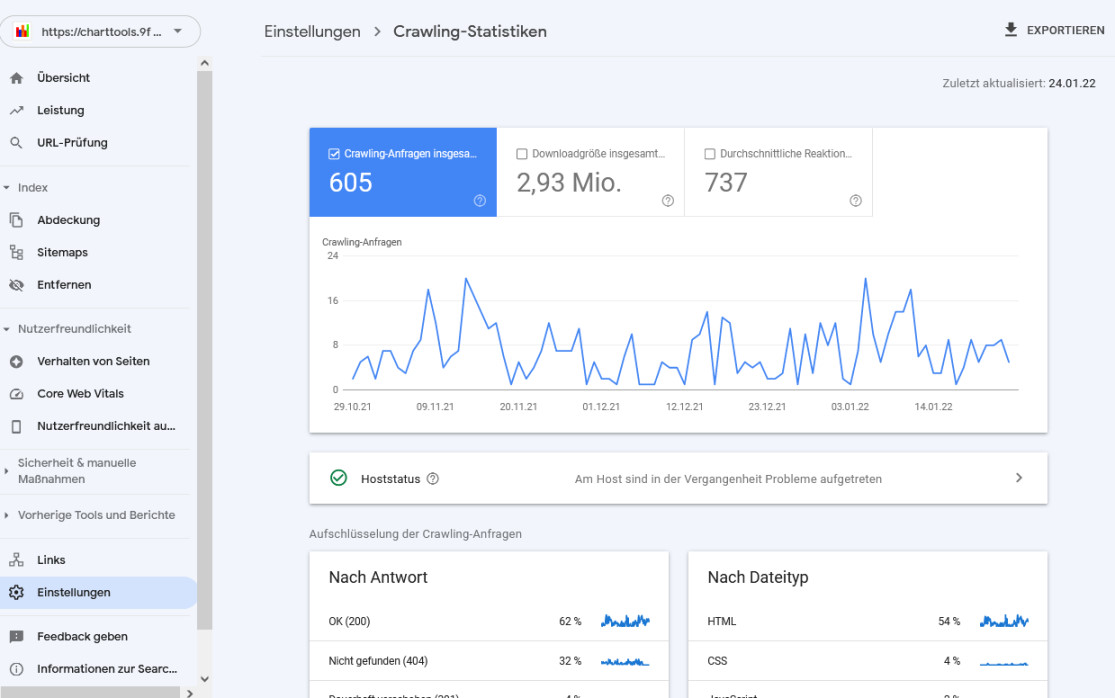
Außerdem wird unter dem Punkt Hoststatus berichtet, dass in der Vergangenheit Probleme aufgetreten sind. Danach werden die Crawling-Abfragen aufgeschlüsselt nach:
- Antwort
- Dateityp
- Zweck
- Googlebot-Typ
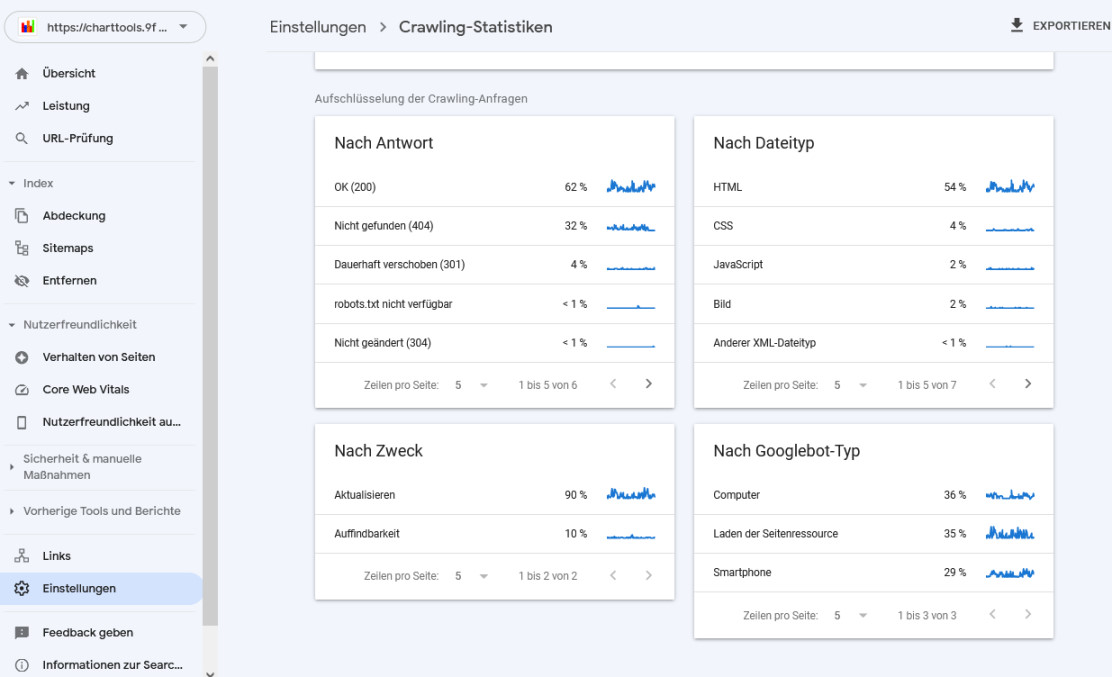
Bei der Aufgliederung nach Antwort fällt auf, dass es einen hohen Anteil von Aufrufen mit dem Fehlercode 404 (nicht gefunden) gibt. Auch hier kann man sich wieder einen detaillierteren Bericht anzeigen lassen:
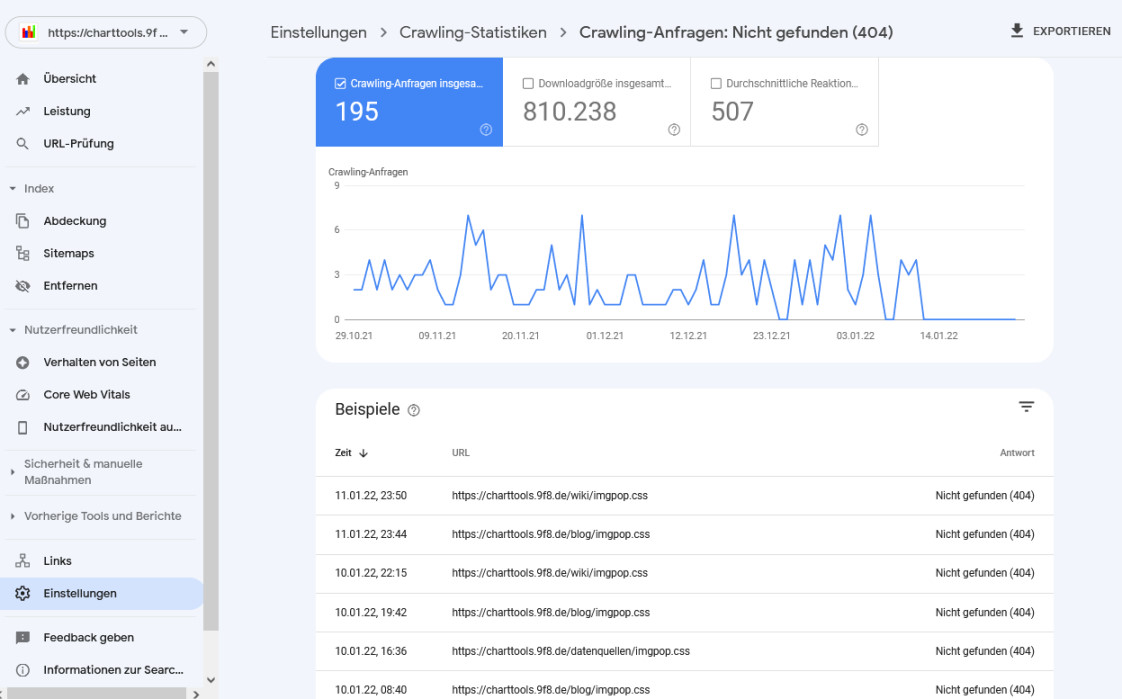
Man sieht, dass eine bestimmte Datei (imgpop.css) immer wieder Fehler produziert hat, allerdings nur bis zum 11.01.2022, danach sackt die Verlaufskurve auf Null ab und es erscheinen keinen weiteren Meldungen. Ganz offensichtlich wurde der Fehler behoben.